




"The Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better-enabling computers and people to work in cooperation.” -Tim Berners-Lee
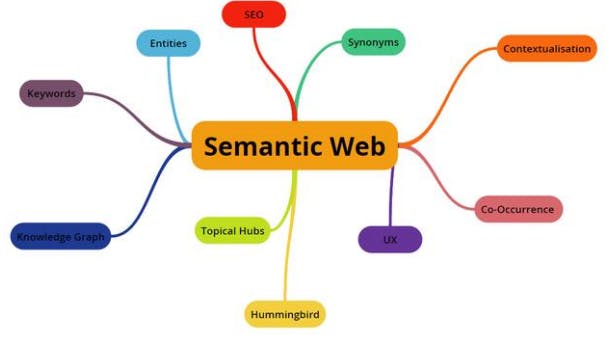
What is semantic web?
The term “Semantic Web” refers to W3C's vision of the Web of linked data. Semantic Web technologies enable people to create data stores on the Web, build vocabularies, and write rules for handling data. Linked data are empowered by technologies such as RDF, SPARQL, OWL, and SKOS. Examples include Best Buy, the BBC World Cup site, Google, Facebook, and Flipboard. Google, Microsoft, Yahoo, etc.
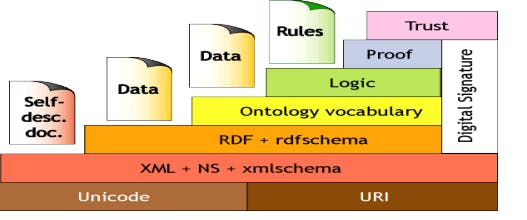
The semantic web and its technologies have been eyed in many fields. They have the capacity to organize and link data over the web in a consistent and coherent way. Semantic web technologies consist of RDF schema, OWL, and rule and query languages like SPARQL and these technologies will help the various domains to resolve their problems. This review paper starts by analyzing the nature of the semantic web and its requirements. We have considered all 10 domains which are closely related to the semantic web and its technologies. To better understand the paper, we have separated it into three major contributions. First, we analyze the semantic web and those domains that increase the growth of the semantic web. Second, we discuss all domains where semantic web technologies play a vital role. Third, we emphasize those domains that go hand in hand with semantic web technologies.
How does it work?
The Semantic Web leads to smarter, more effortless customer experiences by giving the content the ability to understand and present itself in the most useful forms matched to a customer’s need. Semantic standards unlock a crucial evolution of the web towards intelligence that allows the content we post online to be presented in a way that can be understood, connected, and remixed by machines. To understand the principle behind how the Semantic Web evolved, imagine a jukebox. This classic machine plays the song a patron selects through the push of buttons. As the jukebox contains a limited amount of recordings that must be selected manually, the web before semantic technologies were introduced worked in much the same way and had many of the same limitations. Users had to manually pull requests from limited resources: web pages, directories, documents residing on different servers, etc. Machines could not find, read, or let alone use this content.
Why is the semantic web important?
The Semantic Web aims to enrich the Web with a layer of machine-interpretable metadata so that computer programs can predictably derive new information. This goal will require the development of metadata syntax and vocabularies and the creation of metadata for lots of Web pages.
Why should we invest in making our content semantic?
The spread of the Semantic Web and the technologies it brings to the table puts the analytical powers of machines to work in the domains of content production, management, learning, support, media, e-commerce, scientific research, knowledge management, and publishing in general. Anywhere we express knowledge will become semantic. Content discovery and presentation on Google and Bing is only the tip of the iceberg, although SEO and SERP placement might be reason enough. When it comes to the applications of intelligent content, semantic search and smart devices, the emerging semantic web of content and data is a massive opportunity to tap into. Careers, companies, and global innovation leaders will continue to be born on the Semantic Web.
Using Semantic Web Technologies, publishers can:
Build smart digital content infrastructures
Connect content silos across a huge organization
Leverage metadata to provide richer experiences
Curate and reuse content more efficiently
Connect internal and external content sets
Build towards real augmented and artificial intelligence
Power-up authoring experiences and workflow processes
To engineer in such a way that we are planning for the changing content ecosystems, we need to understand the significance of semantic data connections and begin to incrementally embed semantic metadata and relationships into every piece of content we design.
What is the difference between the semantic web and AI?

The association between artificial intelligence and the Semantic Web has a long history. The scenarios put forth in the 2001 Scientific American article that introduced the Semantic Web to the world involved a level of automated decision-making that seemed straight out of an AI textbook. Discussions of ontologies, inference, and description logic merely added to the confusion. However, to equate the Semantic Web with AI is to focus on the semantic aspects while ignoring the Web. In reality, Semantic Web technologies are as much (if not more) about the data as they are about reasoning and logic.
Is the semantic web still used?
Since the early 2000s, the interest in the Semantic Web has been decreasing progressively, as shown in the following figure extracted from Google Trends:
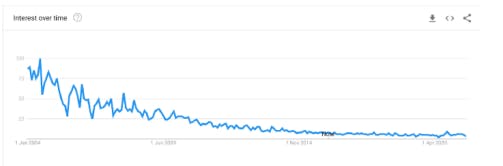
This is probably due to the fact that the great dream of the Semantic Web was already great and too far to be reached, at least for now. In fact, the Semantic Web presents some limitations, such as the following ones: the Web was born as a web of documents, thus it is very difficult to transform every document into data. Many tools and techniques could be used to perform this task, such as Natural Language Processing (NLP), but this requires a lot of time; companies were not sufficiently motivated to release their data as Linked Data, because of the complexity of the RDF format. They prefer to provide data through Web APIs, in the JSON format; many Linked Datasets have poor quality, compared to other kinds of datasets. Thus it is difficult to exploit them for real problems.
The future of the semantic web
Looking at the Linked Data initiative, the story is a bit different. In fact, the interest towards the Linked Data initiative seems to continue over the years, as shown in the following figure, extracted from Google Trends:
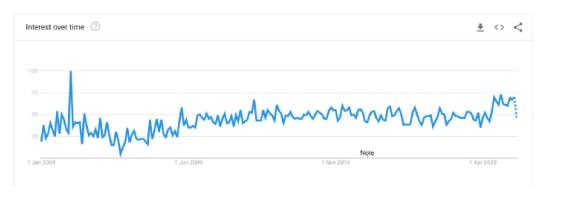
This constant interest in Linked Data topic could be due to the fact that Linked Data still live in communities related to Cultural Heritage, such as museums and archives. Such institutions own a huge quantity of materials and they are moving to release them as Linked Open Data.